Was "Level 5" tatsächlich bedeutet
Dan Shapiros Fünf-Stufen-Modell für agentisches Programmieren gibt eine brauchbare Orientierung für die Reise:
Level 0: KI als bessere Suchmaschine. Du schreibst den Code selbst, KI vervollständigt vielleicht eine Funktion. Jede Zeile wird geprüft.
Level 1: KI für Boilerplate. Du promptest spezifisch und reviewst sofort, Zeile für Zeile.
Level 2: KI als Pair-Programmer. Die KI übernimmt definierte Aufgaben selbstständig. Du reviewst noch immer gründlich, aber nicht mehr jedes einzelne Zeichen.
Level 3: KI als Teammitglied. Die KI generiert den Großteil des Codes. Du reviewst Pull Requests. Du bist nicht mehr Entwickler, sondern Tech Lead mit KI-Contributor.
Level 4: Engineering-Team aus Agenten. Die KI läuft stundenlang autonom. Das System verifiziert sich selbst. Genug Vertrauensinfrastruktur ist vorhanden, dass autonomer Betrieb realistisch ist.
Level 5: Goal Manager. Du beschreibst, was das System tun soll, in einfacher Sprache, User Stories, Kundenanforderungen. Den Code siehst du nicht. Was zählt: Entspricht der Output der Spezifikation? Kannst du ihm genug vertrauen, um ihn zu shippen?
Der Sprung von Level 3 zu Level 5 ist kein Tool-Upgrade. Es ist ein Paradigmenwechsel.
Was wir bei ex-nihilo gelernt haben
Sebastian und Christian haben bei Level 0 begonnen. Beide sind persönlich durch jede Stufe gegangen, nicht durch den Wechsel von Tools, sondern durch die Entwicklung einer anderen Beziehung zum Output der KI.
Heute entwickeln wir Zedl mehrheitlich auf Level 4, mit Teilen auf Level 5. Unser Ziel ist es, vollständig auf Level 5 zu betreiben. Was wir auf diesem Weg gelernt haben:
Der Fortschritt ist persönlich, nicht nur technisch. Jeder Entwickler musste eine eigene Intuition aufbauen, wann er dem Output vertraut, wann er verifiziert und wann er eingreift. Das ist nichts, was man installiert. Es ist etwas, das man entwickelt.
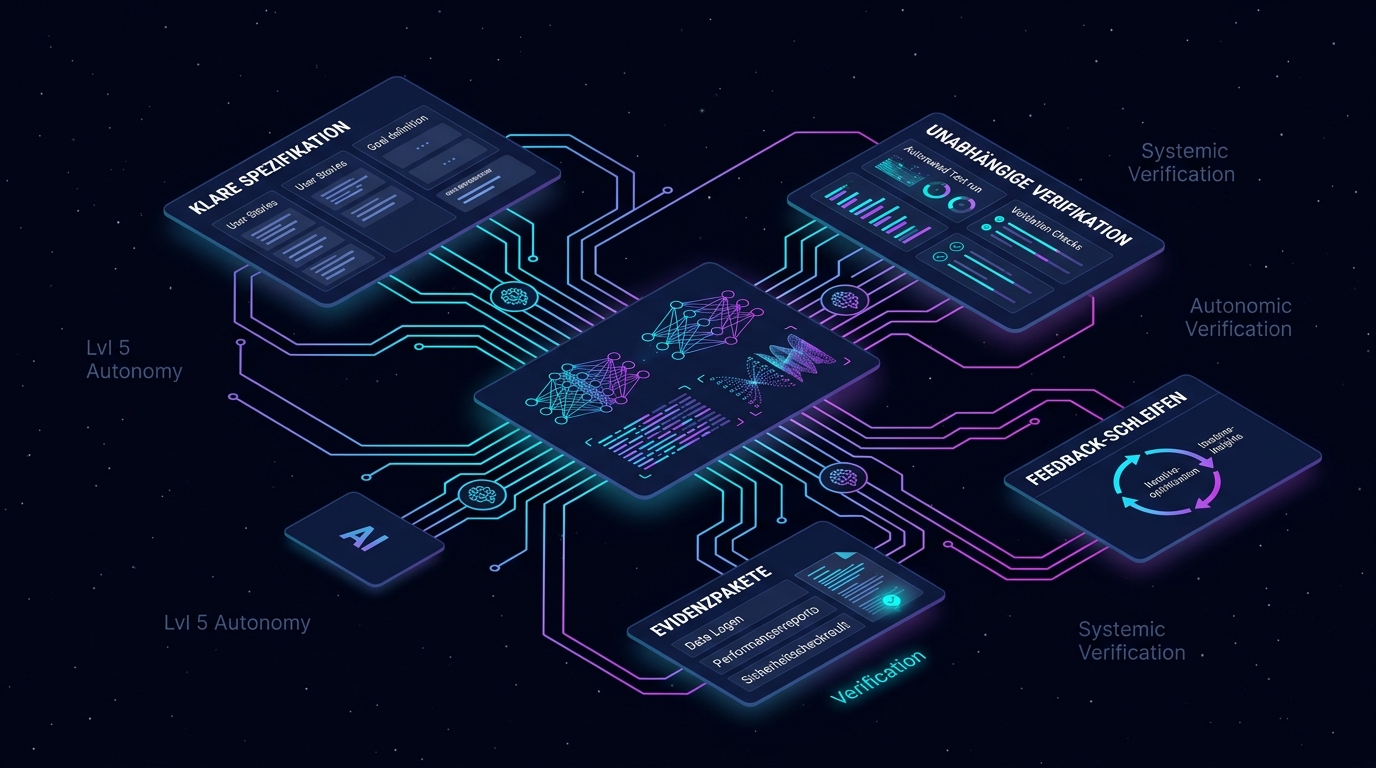
Spezifikationsqualität ist alles. Auf Level 5 ist deine Spezifikation dein Produktmanagement. Eine vage Spec ergibt unvorhersehbaren Output. Wir investieren viel in klare Absichten, Abnahmekriterien und Grenzdefinitionen, nicht weil ein Framework es verlangt, sondern weil die Qualität des Inputs direkt die Qualität des Outputs bestimmt.
Die langweiligen Teile sind die wichtigsten. Das aufregende Gespräch dreht sich um Modelle, Agenten und Capabilities. Das produktive Gespräch dreht sich um Testdesign, Verifikationsstrategien, Evidenzpakete und Eskalationsprotokolle. In der unspektakulären Infrastruktur des Vertrauens wird echte Autonomie aufgebaut.
Tools ändern sich. Prinzipien nicht. Wir haben in den letzten Monaten verschiedene Modelle, IDEs und Konfigurationen genutzt. Was konstant blieb: klar spezifizieren, unabhängig verifizieren, Evidenz aufbauen, Feedback-Schleifen schaffen, Vertrauensgrenzen kennen.
Das Vertrauenssystem im Detail
Wer jetzt fragt "Wie repliziere ich das?" und nach dem passenden Open-Source-Framework sucht, wiederholt den Fehler aus Teil 1 und 2 dieser Serie.
Die richtigen Fragen sind andere:
Welche Evidenz brauche ich, um diesem Output zu vertrauen?
Wenn ein menschlicher Entwickler einen Pull Request einreicht, vertraust du ihm nicht blind. Du vertraust ihm aufgrund von Signalen: Der Code kompiliert, Tests laufen durch, die PR-Beschreibung ergibt Sinn, der Ansatz passt zu Architekturentscheidungen, ein Reviewer bestätigt, dass es richtig aussieht. Vertrauen kommt aus Evidenz, nicht aus Glauben.
Für KI-generierten Output muss dasselbe gelten, mit noch stärkerer Evidenz. Die KI hat nicht den impliziten institutionellen Kontext, den ein erfahrener Engineer mitbringt.
Wie sieht mein Verifikationssystem aus?
Nicht "welches Test-Framework nutze ich", das ist eine Tool-Frage. Die Systemfrage lautet: Welche Kategorien von Evidenz müssen vorhanden sein, bevor ein Output weiterwandert? Tests? Spec-Compliance? Verhaltensvalidierung? Performance? Security-Checks? Und wer oder was prüft jede davon?
Wo sind meine Vertrauensgrenzen?
Nicht jede Aufgabe ist Level-5-bereit. Manche Aufgaben haben mehrdeutige Anforderungen, beinhalten neuartige Architekturentscheidungen, sind sicherheitskritisch oder betreffen kundenseitige Erfahrungen, die menschliches Urteil brauchen. Ein reifes System weiß, wo seine Grenzen sind, und eskaliert dort sauber.
Wie funktioniert meine Feedback-Schleife?
Wenn Output nicht stimmt, und das wird passieren, wie fließt diese Information zurück ins System? Wird die Spezifikation verfeinert? Wird die Verifikation enger gezogen? Bekommt der Agent beim nächsten Mal besseren Kontext? Kontinuierliche Verbesserung ist kein Toyota-Buzzword. Es ist der Mechanismus, der ein fragiles Experiment in eine verlässliche Produktionslinie verwandelt.
Was "der Code interessiert uns nicht mehr" tatsächlich bedeutet
Wenn wir sagen, dass uns der Code auf Level 5 nicht mehr interessiert, ist das bewusst provokativ. Aber es ist wichtig, präzise zu sein.
Das bedeutet nicht, dass uns Qualität egal ist. Es bedeutet, dass sich das primäre Kontrollobjekt verschoben hat. Wir kontrollieren Qualität nicht mehr dadurch, dass wir jede Codezeile lesen. Wir kontrollieren sie, indem wir sicherstellen, dass die Spezifikation präzise ist, die Verifikation rigoros ist, die Tests umfassend sind und das Evidenzpaket vollständig ist.
Das ist nicht weniger Kontrolle. Es ist andere Kontrolle. Genau wie ein CEO eines Fertigungsunternehmens Qualität nicht durch die Inspektion jedes einzelnen Produkts kontrolliert, sondern durch das Design eines Systems, das Fehler erkennt und verhindert.
Wer davon profitiert
- Teams, die mit autonomen Agenten arbeiten und eine systematische Grundlage für Vertrauen aufbauen wollen
- Tech Leads, die den Übergang von "KI-Tool" zu "KI-Produktionssystem" gestalten
- CTOs, die die Implikationen von Level-4/5-Entwicklung für Governance, Qualität und Verantwortlichkeit verstehen müssen
- Alle, die gerade fragen "Welches Framework soll ich verwenden?" und merken, dass das vielleicht die falsche Frage ist
Häufige Fragen
Auf welchem Level arbeitet ex-nihilo heute? Wir entwickeln Zedl mehrheitlich auf Level 4, mit Teilen auf Level 5. Unser Ziel ist es, vollständig auf Level 5 zu betreiben. Das ist ein laufender Prozess, kein Zustand der einfach aktiviert wird.
Was sind die Kosten dieses Übergangs? Der größte Investment ist Zeit, für den Aufbau von Verifikationssystemen, klare Spezifikationsprozesse und die persönliche Entwicklung beider Founder. Es gibt keine Abkürzung durch ein besseres Tool.
Welche Tools nutzt ihr konkret? Aktuell hauptsächlich Claude Code. Aber das ist sekundär. Was primär ist: die Prinzipien, die konstant bleiben, auch wenn sich die Tools ändern. Das ist der Unterschied zwischen einer Tool-Strategie und einer System-Strategie.
Ist Level 5 für jedes Team erreichbar? Ja, aber nicht durch direkten Sprung. Das Modell beschreibt eine Progression. Teams, die versuchen von Level 1 zu Level 5 zu springen, werden scheitern, nicht wegen mangelnder Tools, sondern wegen mangelnder Vertrauensinfrastruktur.
Was passiert, wenn KI-Agenten Fehler machen auf Level 5? Das ist der Punkt, für den das Verifikationssystem existiert. Fehler sind kein Versagen von Level 5 als Konzept. Sie sind ein Signal, dass eine Vertrauensgrenze nicht korrekt gesetzt war oder das Verifikationssystem eine Lücke hat. Diese Information geht zurück in die Spezifikation und die Verifikationsregeln.
Können wir mit ex-nihilo über diesen Aufbau sprechen? Ja. Wir teilen, was wir gelernt haben, weil die wichtigsten Gespräche in der Branche gerade über Systeme und Prinzipien geführt werden sollten, nicht über Tools. Schreibt uns unter info@ex-nihilo.digital.